
Security and user-friendliness are not always at ends, but making a product that is simultaneously user-friendly and secure is harder than a making product that accomplishes only one of those goals. In the battle to balance security and usability, usernames are a topic that is hotly debated amongst software developers and security evaluators. Because usernames are integral to both security and usability, the methodology for choosing, verifying, and protecting usernames is important.
In order for an attacker to access a particular account without permission, she must first locate it by determining an account identifier. More often than not, this is easy. Many websites use email addresses as a username — check your spam folder if you’re unsure about how difficult it is for attackers to obtain those. Other websites allow you to choose your own unique username, but these are often simple to enumerate or guess. We have trained users to regard passwords as extremely private, but to regard usernames as semi-public. Usernames are casually posted on forums, found within contact lists, and included in high score records. We also regularly caution users not to reuse passwords between websites, but rarely warn them not to reuse usernames. To make matters worse, websites often impose greater restrictions on the length and complexity of usernames than with passwords. Software companies have been training users for decades to create simple usernames that they reuse ubiquitously, and then to casually post these usernames all over the Internet. It’s an account identification picnic for hackers.
Because locating user accounts is such a fundamental step in account compromise, websites can help to protect their users by preventing the enumeration of accounts. Typically, an attacker will check whether a given string is a valid username through a login form, “forgot password” page, or similar section of a website. Some websites, such as Google, prevent this check by returning a generic error message that is identical regardless of whether the account name you’re trying to access is legitimate or not:
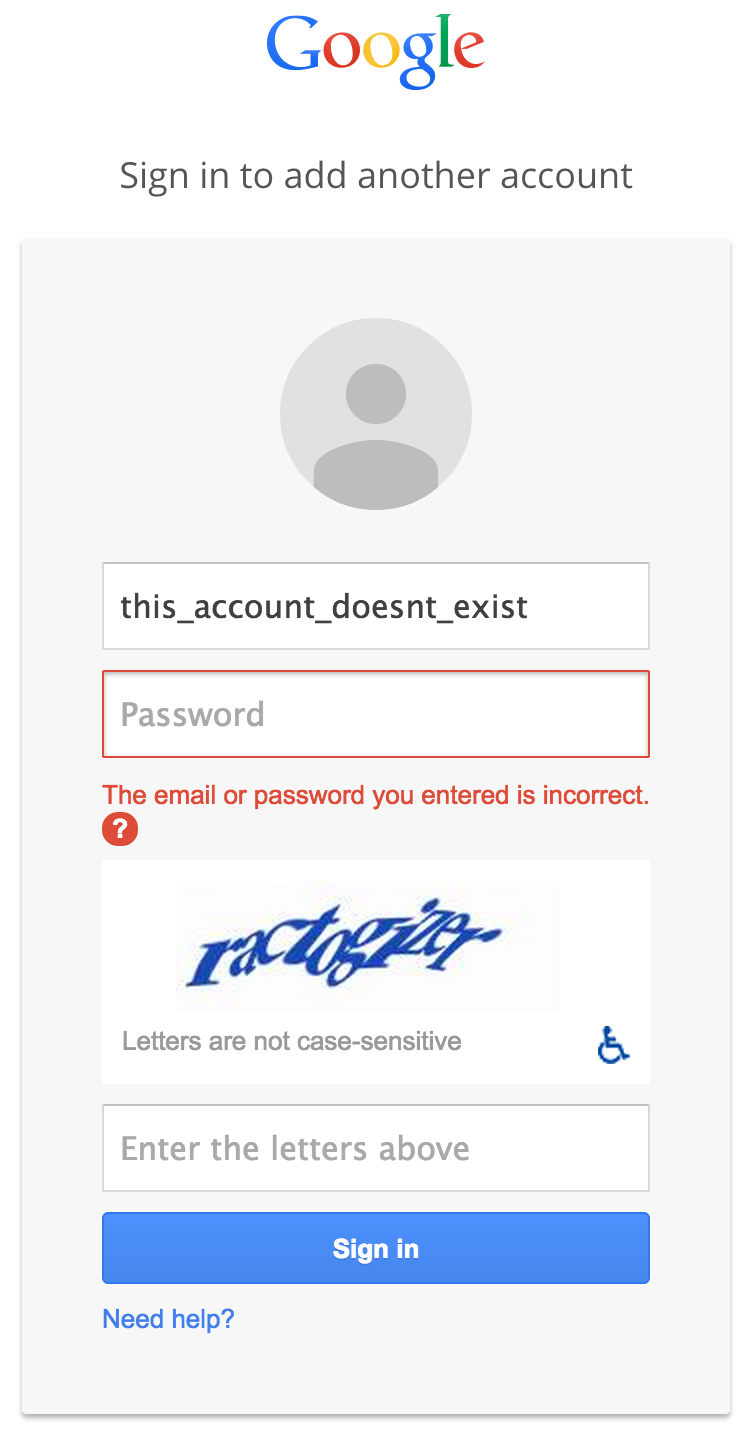
That can be confusing and frustrating for users who are not quite sure what their usernames are, and so other websites, such as Bank of America, provide more specific error messages at the cost of permitting account enumeration:
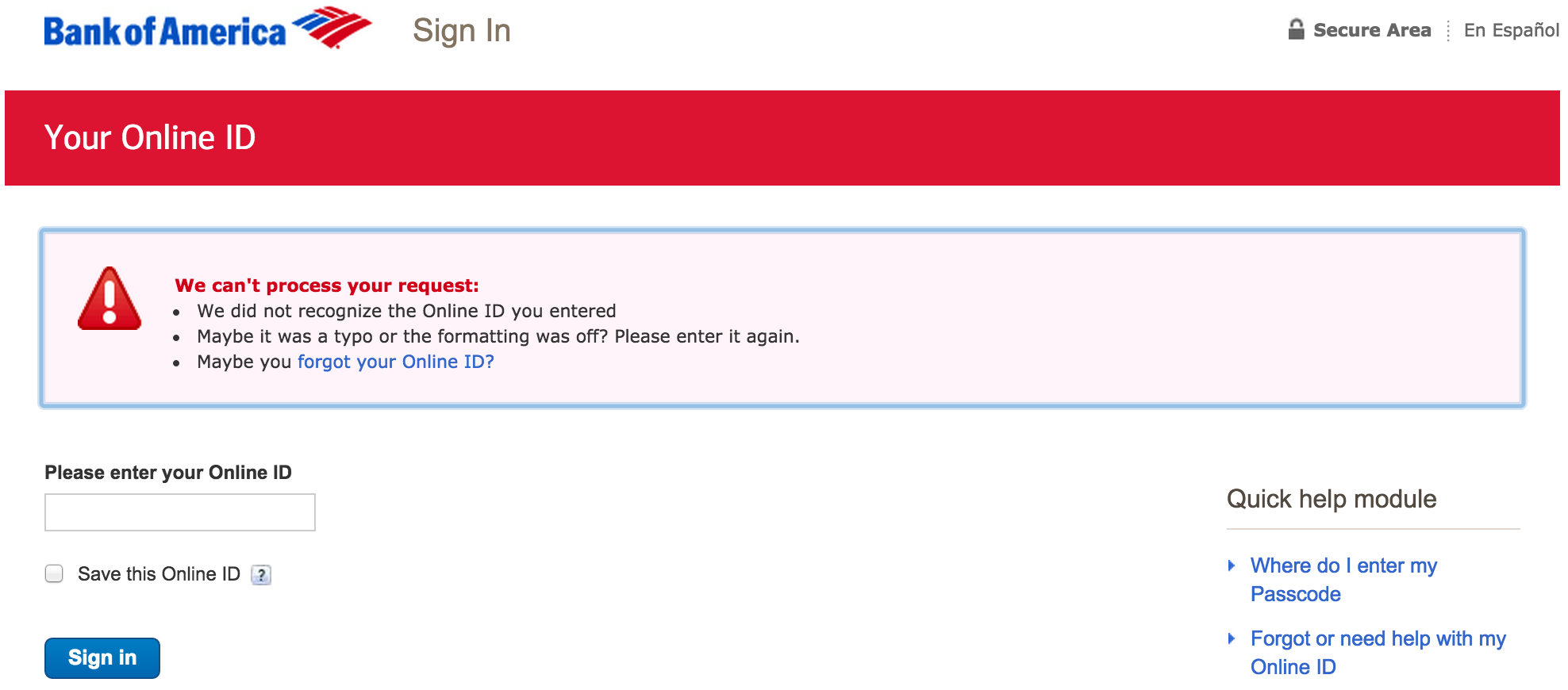
Blockchain.info also provides specific error messages when someone tries to login with an invalid username, but due to the way that we handle usernames, it’s not risky.
Early on, Blockchain.info made the design decision to generate random user identification strings. This is achieved by using Java’s Universally Unique Identifier (UUID) class. This class creates a random string separated by some hyphens that looks something like this:
a0d908fe-f20e-4fdc-868b-9c5e8ae01b73
It’s an unusual approach, and can be a little confusing to new users. Luckily, a lot of our new users start out by using our mobile wallets, which hide this inscrutable-looking string from them, and use other means to maintain their authentication. On the other hand, one of the upsides to this is that it is much more difficult for an attacker to guess that someone’s username is “a0d908fe-f20e-4fdc-868b-9c5e8ae01b73” than “jsmith1776.”
How difficult? Imagine an attacker who was able to submit 400,000 guesses to our website per second. That’s an extraordinary number of guesses, but it was the peak number of requests per second that Reddit experienced during a recent Denial of Service attack. If an attacker maintained that rate over 10 years, he would still only have a $ 0.0000000170\% $ chance of finding anyone else’s account. He is much more likely to win the Powerball lottery ($ 0.000000571\% $). If his guessing rate doubled every year — a change that would be extraordinary, since many people have observed that networking capacity has failed to adhere to Moore’s Law — he would still only have a $ 0.00000173\% $ chance.

Here’s how I calculated that probability:
Suppose we have $ w $ wallets created so far, each with it’s own unique UUID. Also suppose that there are $ v $ possible values that can be generated for the UUID. Once an attacker has generated a random UUID, the chance that it coincidences with one of the previously generated UUIDs is $ \frac{w}{v} $. If the attacker fails to find someone else’s previously generated UUID with the first guess and generates a second UUID, his chance the second time around is $ \frac{w}{v -1} $ since he already eliminated one possibility on the first guess. His combined chance for two guesses is $ \frac{w}{v} + \frac{w}{v-1} $. If we generalize this to calculate his chances after $ n $ guesses using Sigma summation notation, we get:
$$ \sum\limits_{i=0}^{n-1} \frac{w}{v-i} $$
The Java UUID class generates identifiers using 112 bits of entropy by taking 128 bits from a secure pseudo-random number generator and replacing 16 of those bits with static values. In other words there are $ v=2^{112} $ possible values for a random UUID.
If everyone in the world had a wallet ($ w = 7\times10^9 $ wallets), and the attacker checked 400,000 UUIDs per second over 10 years ($ n = 400000 \times 60 \times 60 \times 24 \times 365 \times 10 \approx 1.26\times 10^{14} $), then we can calculate his chance of success:
$$ \sum\limits_{i=0}^{1.26\times10^{14}} \frac{7\times10^9}{2^{112}-i} \approx 0.0000000170\% $$
If the attacker doubles his capacity every year over ten years ($ n \approx 1.29\times10^{16}$), then his chances rise to: $ 0.00000173\% $
The bottom line is that the usernames of Blockchain.info users are well defended against account enumeration attacks, even though we do provide specific feedback about UUID validity on our login area and two-factor authentication reset forms. This demonstrates one of the security features of assigning random identifiers to users, rather than relying on the somewhat questionable intuitions that software services have instilled within users over the last couple decades.